
Image-to-Text Prompt Generators: Midjourney /describe, CLIP Interrogator, Llava
Image-to-text AI tools offer an easy approach to coming up with creative text prompts that can be used in AI image generators such as MidJourney, DALL-E, Stable Diffusion, etc.
If you have questions like "how should i write my prompts" or "what words should i use", image-to-text generators can be a valuable resource.
By simply uploading a reference image, these AI-powered generators can provide descriptions, keywords, or even sample prompts.
In this article, I'll delve into three image-to-text tools: Midjourney’s /describe command, CLIP Interrogator, and Llava.
I'll show you how to use them (with example results) and provide comments on cost, speed, and my overall impressions. I hope this article helps you find the inspiration you need to create your next text prompt!
How to use MidJourney’s /describe feature: Image-to-Text
How to use CLIP Interrogator: Image-to-Text
How to use Llava: Large Language and Vision Assistant: Image-to-Text
Overall impressions, cost, and speed
How to use MidJourney’s /describe feature: Image-to-Text
You must have an active MidJourney membership in order to use the /describe image-to-text feature.
In Discord, type /describe where you normally type /imagine, and then hit the spacebar
Drag and drop your image file into the window or click to upload, and press Enter
MidJourney will give you 4 prompt suggestions based on your image
Click one of the numbered buttons below your image to automatically submit an /imagine command for the prompt, or click “Imagine all” to submit all 4
Click the re-roll button to generate new text prompts


How to use CLIP Interrogator: Image-to-Text
CLIP Interrogator is a free online tool. Submit your reference image and have it return either a sample text prompt or a categorized list of keywords.
Open the webpage https://huggingface.co/spaces/pharma/CLIP-Interrogator in your browser
With the “Prompt” tab selected, drag and drop your image or click to upload
Click submit
Review your prompt suggestion. Getting results can take a few minutes, depending on the queue.
For more prompt ideas, click on the “Analyze” tab
Re-upload your image and click the “Analyze” button
Review keyword ideas for the different categories provided



How to use Llava: Large Language and Vision Assistant: Image-to-Text
Llava is a free online tool where you upload your reference image and interact with a chatbot, similar to ChatGPT.
Open the webpage https://llava-vl.github.io/ in your browser
Drag and drop or click to upload your image file
Ask the chatbot a question about your image or give it a command - if you’ve used ChatGPT, this follows the same premise
Read what the chatbot has to say



Overall impressions, cost, and speed
All three of these image-to-text prompt tools are user-friendly and easy to navigate. Out of the three, MidJourney is the only one that requires a monthly membership. All three tools are fast (once processing starts), however, the queue for CLIP Interrogator can impede working quickly. For me, the queue added 3-4 minutes wait time for each image I gave it.
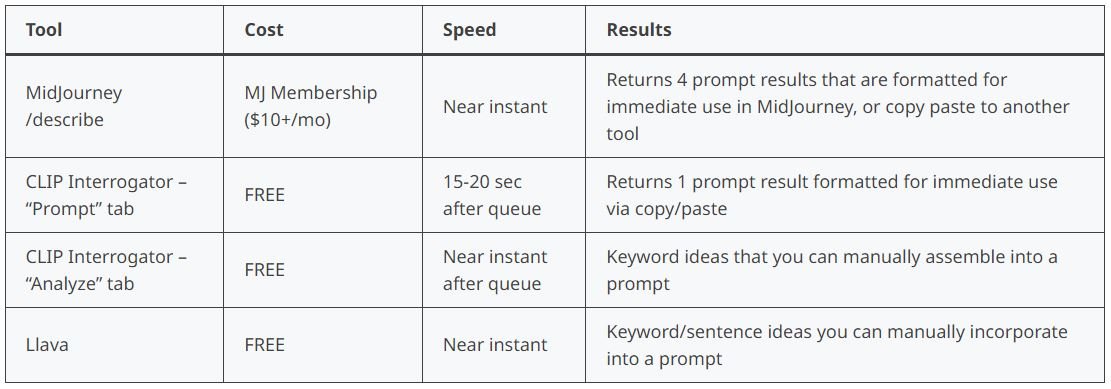
My favorite image-to-text prompt tool is (of course) MidJourney’s /describe feature. I love the convenience of immediately rolling the multiple sample prompts for image generation. I also find the keywords and phrases insightful, especially for learning about general art styles and unique descriptive words.
If MidJourney's sample prompts include an artist's name, you'll find a hyperlink that takes you directly to Google search results for that artist. This feature allows you to see why MidJourney included that particular artist in the prompt. Although I don't use artist names in my prompts (unless for demo purposes), I appreciate the opportunity to explore different artists that MidJourney identifies as potential inspirations for the reference image.
CLIP Interrogator's prompt output is pretty good and it's already in a format that can be copied and pasted into your favorite text-to-image generator. I found the results in the “Analyze” tab helpful for exploring different keywords and phrases that I might consider for a text prompt. However, there were too many phrases like "x contest winner" and "featured on x", which I don't find very useful. CLIP Interrogator was made with Stable Diffusion in mind, so perhaps keyword phrases like that are more impactful there.
Llava's interactive approach was an interesting concept to explore. Unlike MidJourney and CLIP Interrogator, where results are static, Llava allows you to engage and ask questions chatbot-style. Being able to interact this way made me feel like I had some influence over the type of output I received.
However, I struggled to get Llava to return comma-separated keywords and key phrases. Instead, the tool tended to form sentences, even when I told it not to. With all image-to-text tools, some inaccuracies are expected. I had a curious case with Llava where it said the dog in my image (shown above) was brown and white, but that the overall style of the image was black and white. Despite this, Llava provided an engaging experience that could allow for more personalized results.
I hope you found this article useful, if so, please share it and let me know in the comments!